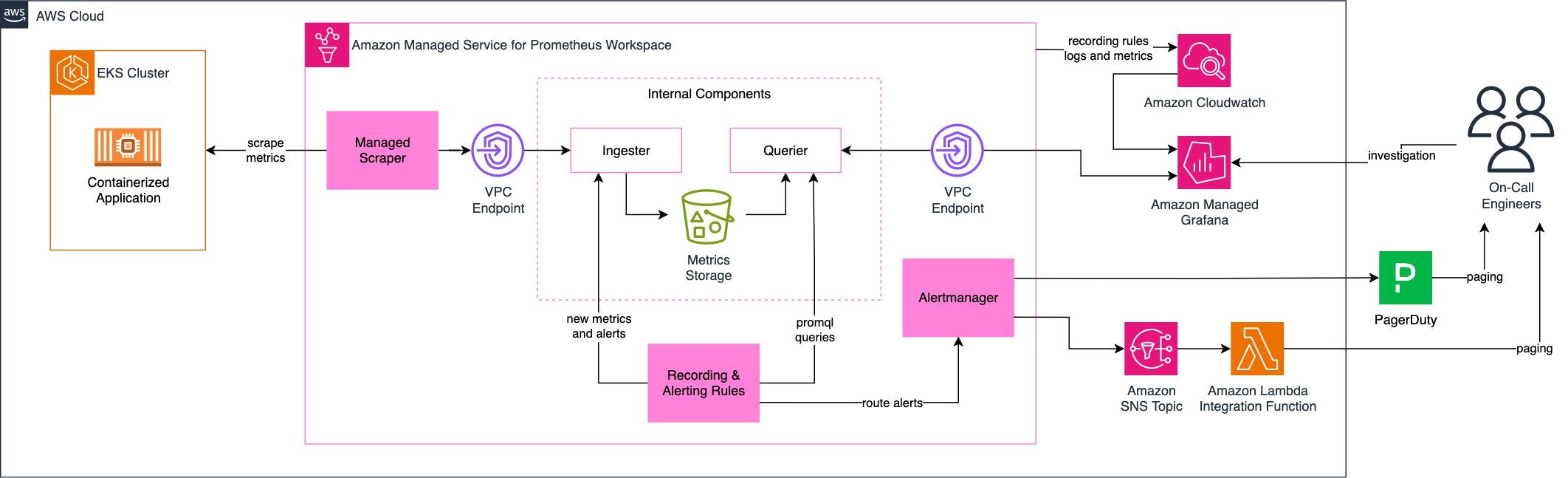
Dalam dunia IT modern, terutama yang menggunakan sistem berbasis cloud dan container, monitoring saja tidak cukup. Kita juga membutuhkan alert (peringatan) agar bisa langsung bertindak saat terjadi masalah. Di sinilah peran penting alerting—menghubungkan data (metrics) dengan aksi nyata.
Pada artikel ini, kita akan membahas bagaimana cara mengelola alert dengan baik menggunakan Amazon Managed Service for Prometheus dengan bahasa yang sederhana dan mudah dipahami.
Apa Itu Alerting dan Kenapa Penting?
Alert adalah notifikasi otomatis yang muncul ketika sistem mendeteksi kondisi tertentu, misalnya:
-
CPU terlalu tinggi
-
Error aplikasi meningkat
-
Server tidak merespons
Dengan alert yang tepat, tim IT bisa:
-
Mengetahui masalah lebih cepat
-
Mengurangi downtime
-
Menjaga layanan tetap stabil
Namun, jika tidak diatur dengan baik, alert bisa terlalu banyak (alert fatigue) dan justru membuat tim kewalahan.
Gambaran Sistem Monitoring
Bayangkan sebuah perusahaan (misalnya Example Corp) yang menggunakan sistem berbasis container di cloud. Mereka menggunakan:
-
Kubernetes (untuk menjalankan aplikasi)
-
Prometheus (untuk mengumpulkan data)
-
AWS (untuk mengelola semuanya)
Dalam sistem ini:
-
Aplikasi mengirim data seperti CPU, memori, dan error
-
Prometheus mengumpulkan data tersebut
-
Alert akan muncul jika ada kondisi tertentu
Komponen Penting dalam Sistem Alerting
Berikut komponen utama yang perlu Anda pahami:
1. Recording Rules
Digunakan untuk menghitung dan menyimpan data tertentu agar lebih cepat diakses.
Contoh sederhana: menghitung jumlah error dalam 5 menit terakhir.
Manfaatnya:
-
Mempercepat query
-
Memudahkan pembuatan alert
2. Alerting Rules
Digunakan untuk menentukan kapan alert harus muncul.
Contoh:
-
Jika CPU > 80% selama 5 menit → kirim alert
Alert yang baik harus:
-
Jelas
-
Mudah dipahami
-
Bisa langsung ditindaklanjuti
3. AlertManager
Berfungsi untuk mengatur bagaimana alert dikirim.
Fitur utamanya:
-
Mengelompokkan alert
-
Menghindari notifikasi berulang
-
Mengirim ke berbagai tujuan (email, SMS, dll)
4. Integrasi Notifikasi
Alert bisa dikirim ke:
-
Amazon Simple Notification Service (SNS)
-
PagerDuty (untuk tim on-call)
Ini memastikan tim langsung tahu saat ada masalah.
Contoh Kasus Sederhana
Misalnya, Anda ingin memantau error pada aplikasi.
Langkahnya:
-
Hitung jumlah error (recording rule)
-
Tentukan batas (misalnya >10%)
-
Buat alert jika batas terlampaui selama 5 menit
Hasilnya:
-
Sistem akan otomatis memberi tahu jika error meningkat
-
Tim bisa langsung melakukan perbaikan
Cara Mengatur Alert dengan Baik
Berikut beberapa tips penting:
🔹 Gunakan Threshold yang Masuk Akal
Jangan terlalu sensitif, agar tidak terlalu banyak alert.
🔹 Gunakan Delay (for: 5m)
Pastikan masalah benar-benar terjadi, bukan hanya sementara.
🔹 Gunakan Label dan Deskripsi
Tambahkan informasi seperti:
-
Tingkat keparahan (warning, critical)
-
Tim yang bertanggung jawab
-
Link dashboard atau panduan (runbook)
Menghindari Alert Fatigue
Alert fatigue terjadi ketika terlalu banyak notifikasi masuk, sehingga tim jadi mengabaikannya.
Cara menghindarinya:
-
Gunakan grouping di AlertManager
-
Gabungkan alert yang mirip
-
Atur interval notifikasi
Dengan begitu, tim hanya menerima alert yang benar-benar penting.
Monitoring Performa Alert
Setelah sistem berjalan, Anda juga perlu memantau performanya.
Beberapa hal yang bisa dipantau:
-
Waktu evaluasi alert
-
Jumlah error saat evaluasi
-
Jumlah rule yang dijalankan
Anda bisa menggunakan Amazon CloudWatch untuk melihat:
-
Log
-
Metric
-
Error
Ini membantu memastikan sistem alert berjalan dengan baik.
Visualisasi dengan Dashboard
Agar lebih mudah dipahami, semua data bisa ditampilkan dalam dashboard, misalnya menggunakan Grafana.
Dashboard ini bisa menunjukkan:
-
Status alert (aktif atau tidak)
-
Riwayat alert
-
Performa sistem
Dengan tampilan visual, tim bisa lebih cepat memahami kondisi sistem.
Contoh Masalah dan Solusinya
Misalnya:
-
Alert tidak pernah muncul
-
Data tidak terlihat di dashboard
Langkah troubleshooting:
-
Cek apakah rule sudah dibuat
-
Lihat log error
-
Jalankan query secara manual
-
Perbaiki jika ada kesalahan
Dengan pendekatan ini, masalah bisa ditemukan dan diperbaiki dengan cepat.
Kesimpulan
Alerting adalah bagian penting dari sistem monitoring modern. Dengan menggunakan layanan seperti Amazon Managed Service for Prometheus, Anda bisa membangun sistem alert yang:
-
Cepat
-
Efisien
-
Mudah dikelola
Kunci utamanya adalah:
-
Menggunakan recording dan alerting rules dengan benar
-
Mengatur notifikasi dengan baik
-
Menghindari alert yang berlebihan
Dengan strategi yang tepat, Anda tidak hanya memantau sistem, tetapi juga bisa mencegah masalah sebelum menjadi besar.
Bagi pemula, mulailah dari yang sederhana: buat satu alert penting, pahami cara kerjanya, lalu kembangkan secara bertahap. Dengan begitu, sistem Anda akan semakin andal dan siap menghadapi berbagai tantangan di dunia IT modern.
Infrastruktur IT yang kuat adalah kunci produktivitas perusahaan. Dengan aws cloud indonesia, merupakan bagian dari PT. iLogo Indonesia, yang merupakan mitra terpercaya dalam solusi Infrastruktur IT dan Cybersecurity terbaik di Indonesia.
Hubungi kami sekarang atau kunjungi awscloud.ilogoindonesia.id untuk informasi lebih lanjut!